⚡ Gremlin
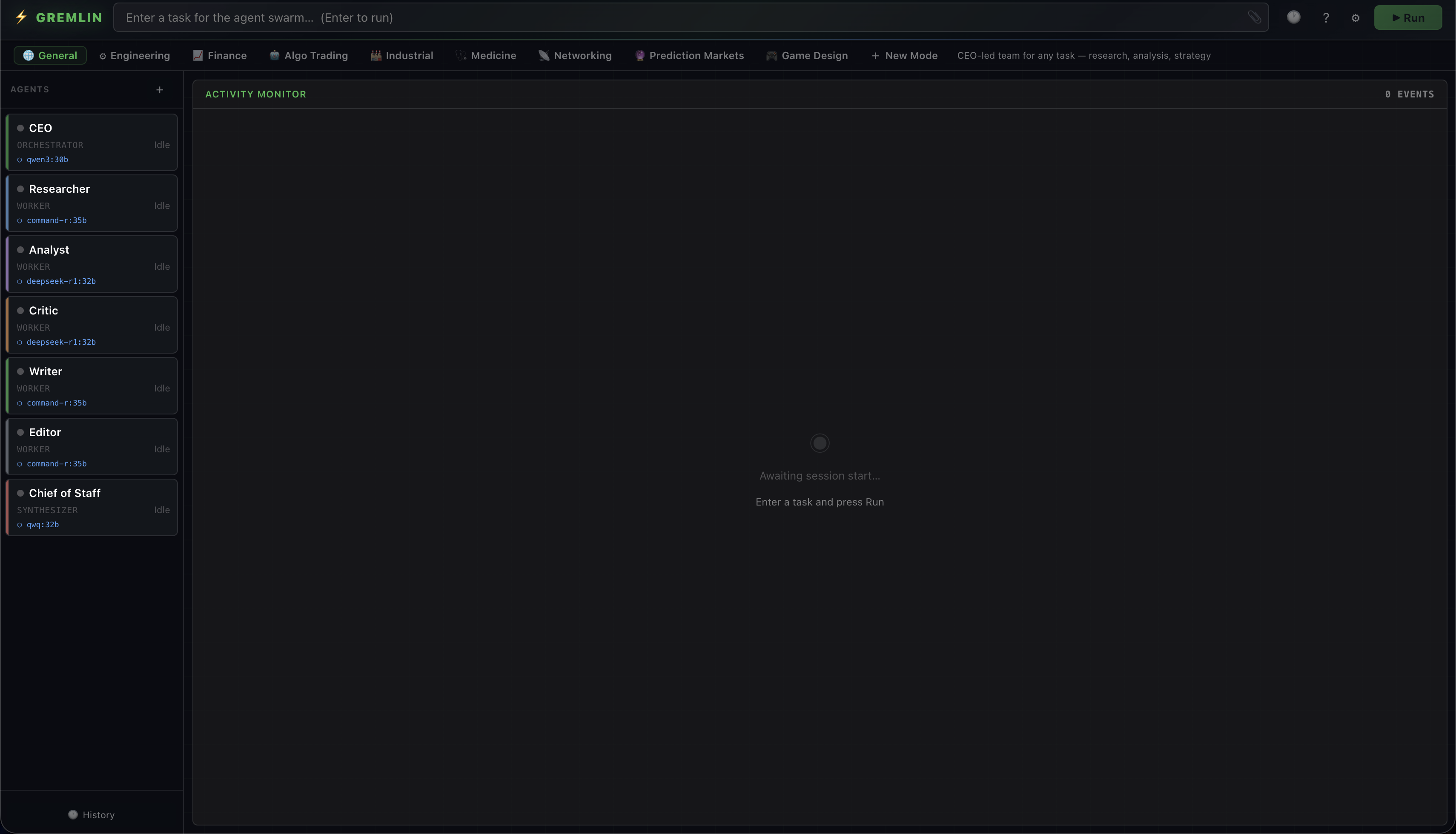
A browser-native multi-agent coordinator. Spin up a team of AI agents that message each other, call tools, and converge on a result — using any model you choose: local (Ollama, LM Studio, WebLLM) or cloud (OpenAI, Anthropic, Gemini, Groq, OpenRouter, Together, or any OpenAI-compatible endpoint). No server required.